Viele moderne Anwendungen basieren auf der kontinuierlichen Transformation und Korrelation von Daten. Gehostete Dienste wie Azure Data Factory eignen sich dabei für Entwickler, die sich traditionell weniger mit diesem Thema befassen müssen. Hier eine kleine Einführung.
In Zeiten von Big Data werden unorganisierte Rohdaten häufig in relationalen, nicht relationalen und anderen Speichersystemen gespeichert. Allerdings mangelt es den Rohdaten an Kontext bzw. an der nötigen Aussagekraft, um von Analysten und Analystinnen, Datenfachleuten oder Entscheidungsträgern in Unternehmen sinnvoll genutzt werden zu können.
Für Big Data ist ein Dienst zum Orchestrieren und Operationalisieren von Prozessen erforderlich, mit dem sich diese enormen Rohdatenmengen in verwertbare geschäftliche Erkenntnisse verwandeln lassen. Azure Data Factory ist ein verwalteter Cloud-Dienst für komplexen Hybridprojekte mit ETL (Extrahieren, Transformieren und Laden), ELT (Extrahieren, Laden und Transformieren) und Datenintegration. Azure Data Factory ermöglicht also das Erstellen datengesteuerter Workflows für die Orchestrierung von Datenverschiebungen und die skalierte Transformation von Daten. So erstellen und planen Sie mit ADF datengesteuerte Workflows (so genannte Pipelines), die Daten aus unterschiedlichen Datenspeichern aufnehmen können, erstellen komplexe ETL-Prozesse, die Daten visuell mit Datenflüssen transformieren oder verwenden Compute-Services wie Azure HDInsight Hadoop, Azure Databricks und Azure SQL Database.
Transformierte Daten lassen sich darüber hinaus in Datenspeichern wie z. B. Azure Synapse Analytics veröffentlichen, damit BI-, sprich Business-Intelligence-Anwendungen sie verwenden können. Über Azure Data Factory lassen sich Rohdaten letztendlich in aussagekräftigen Datenspeichern und Data Lakes organisieren und für bessere geschäftliche Entscheidungen verwenden.
Jedes Azure-Abonnement kann über mindestens eine Azure Data Factory-Instanz (bzw. Data Factory) verfügen. Azure Data Factory besteht aus den folgenden Hauptkomponenten:
Pipelines: Bei einer Pipeline handelt es sich um eine logische Gruppierung von …
… Aktivitäten, die zusammen eine Aufgabe (Task) bilden. Die Aktivitäten in einer Pipeline definieren Aktionen, die sich auf Daten anwenden lassen. Ein …
… Datensatz (Dataset) ist eine benannte Ansicht von Daten, die einfach auf die Daten verweist, die in den Aktivitäten als Ein- und Ausgabe verwendet werden sollen. Datasets bestimmen Daten in verschiedenen Datenspeichern, z.B. Tabellen, Dateien, Ordnern und Dokumenten. Ein Azure-Blob-Dataset kann beispielsweise den Blob-Container und -Ordner in Blob Storage angeben, aus dem die Aktivität die Daten lesen soll. Bevor ein Dataset generiert wird, muss man einen …
… verknüpften Dienst erstellen, um Datenspeicher und Dienst zu verbinden. Verknüpfte Dienste ähneln Verbindungszeichenfolgen, mit deren Hilfe die Informationen definiert werden, die der Service zum Herstellen einer Verbindung mit externen Ressourcen benötigt. Genau genommen stellt das Dataset die Struktur der Daten innerhalb des verknüpften Datenspeichers dar, während der verknüpfte Dienst die Verbindung mit der Datenquelle definiert. Ein mit Azure Storage verknüpfter Dienst verbindet z. B. ein Speicherkonto. Ein Azure-Blob-Dataset repräsentiert den Blob-Container und ggf. den Ordner innerhalb des Azure Storage-Kontos, das die zu verarbeitenden Eingabe-Blobs enthält.
Datenflüsse schließlich sind eine Ergänzung zum Konzept der Pipelines. Während Pipelines große Mengen von Daten bewegen, dienen Data Flow dazu, die Daten zu modifizieren, Spalten hinzuzufügen oder anhand bestimmter Werte zu transformieren.
Im folgenden Beispiel-Szenario setzen wir die Azure Data Factory als ETL-Werkzeug ein, um umfangreiche Rohdaten im Parquet-Format einzulesen und in verwertbare Daten in Form einer Azure-SQL-Datenbank zu transformieren.
Open Datasets
Wie oben einleitend erläutert, stellt der Datenbewegungsprozess mit oder ohne Transformation im Rahmen eines ETL-Prozesses allerdings nur einen kleinen Ausschnitt der Mächtigkeit von Azure Data Factory dar. In unserem folgenden Beispiel sind die Rohdaten die Bewegungsdaten New Yorker Taxis – hier aus dem Monat 01/2022 –, welche die Stadt kontinuierlich zur Verfügung stellt.
Woher man solche Datenquellen kennt? Microsoft verweist darauf in seiner Dokumentation zu öffentlichen Datasets. Wer genauer hinsieht stellt auch schnell fest, dass die Daten faktisch in einen öffentlichen zugänglichen Amazon-S3-Bucket bereitgestellt werden. Bis ca. Mitte 2019 standen die Daten im CSV-Format als kommaseparierte Liste zur Verfügung, neuere Daten liegen im sogenannten Apache-Parquet-Format vor.
Apache Parquet
Apache Parquet ist ein Dateiformat, das entwickelt wurde, um eine schnelle Datenverarbeitung für komplexe Daten zu unterstützen, mit mehreren bemerkenswerten Eigenschaften: Im Gegensatz zu zeilenbasierten Formaten wie CSV ist Apache Parquet spaltenorientiert. Zudem ist Parquet kostenlos, quelloffen (unter der Apache-Hadoop-Lizenz) und kompatibel zu den meisten Hadoop-Datenverarbeitungs-Frameworks. Zudem sind in Parquet die Metadaten, einschließlich Schema und Struktur, in jede Datei eingebettet, was es zu einem selbstbeschreibenden Dateiformat macht.
Vorarbeiten
Wir wollen nun diese öffentlichen Parquet-Data in einen Azure-Blob-Container laden und von dort aus automatisiert mit Hilfe der Azure Data Factory so aufbereiten, dass sie in einer verwaltete Azure-SQL-Datenbank ablegt werden und vor dort aus mittels SQL abgefragt werden können. Die Sinnhaftigkeit des Szenarios steht hierbei nicht so sehr im Vordergrund; es geht nur um den Tansformations/ETL-Prozess.
Für die vorbereitenden Maßnahmen wie das Erstellen des Speicherkontos, des SQL Servers, der SQL-Datenbank und der Data Factory bedienen wir uns der Einfachheit und Schnelligkeit halber der Kommandozeile; diesmal der Azure-CLI. Alle Vorgänge funktionieren aber auch per Powershell oder im Azure-Portal. Die verwendeten Ressource-Namen sind selbstverständlich beispielhaft zu verstehen.
Beginnen wir mit dem Erstellen einer Ressourcengruppe:
az group create -l germanywestcentral -n dridfdemo-rgDann erstellen wir den Storage Account…
az storage account create -n dridfdemosa -g dridfdemo-rg -l germanywestcentral --sku Standard_LRS… und nun den SQL Server für die SQL-Datenbank (Achtung, hier das Passwort entsprechend anpassen):
az sql server create -n dridfdemosqlserver -g dridfdemo-rg -l germanywestcentral --admin-user sqladmin --admin-password Pa55w.rd1234Fehlt noch die Datenbank selbst auf diesem Server:
az sql db create -n dridfdemodb --server dridfdemosqlserver --resource-group dridfdemo-rg --edition BasicHier verwenden wie zum Kostensparen den Dienstplan „DTU-basiert“ in der Basic-Edition mit 5 DTUs. Wahlweise ließe sich auch das V-Core-Model im serverlosen Modell verwenden. Dann brauchen wie noch zwei obligatorische SQL-Server Firewall Regeln. Die Erste erlaubt den Zugriff von allen anderen Azure-Diensten:
az sql server firewall-rule create --name “AllowAZureServices” --resource-group dridfdemo-rg --server dridfdemosqlserver --end-ip-address 0.0.0.0 --start-ip-address 0.0.0.0Die Zweite erlaubt zusätzlich den Zugriff nur von der eigenen IP-Adresse. Hier müssen Sie die momentane Public-IP IHRES Routers einsetzen:
az sql server firewall-rule create --name “AllowHomeIP” --resource-group dridfdemo-rg --server dridfdemosqlserver --end-ip-address 84.150.179.201 --start-ip-address 84.150.179.201Datenbasis besorgen und in Speicherkonto hochladen
Wie oben geschildert findet sich passende Quelldaten der New Yorker Taxis Amazon S3 unter: https://s3.amazonaws.com/nyc-tlc. Verwenden Sie nur diesen Teil des Links, erhalten Sie öffentlichen Lesezugriff auf den ganzen S3-Bucket und können dann alle Datensätze sehen. Den Key für die Daten von Januar 2022 im Parquet-Format hängen Sie dann einfach an. Zuvor brauchen Sie aber einen der zwei Speicherkontoschlüssel. Diesen ermitteln Sie mit …
az storage account keys list --account-name dridfdemosaDiesen Schlüssel verwenden Sie dann zum Anlegen des Containers „source-data“.
az storage container create --name source-data --account-key <key> --account-name dridfdemosaNun können Sie die Datei aus den oben genannten S3-Bucket in Azure Blob hochladen:
az storage blob copy start --destination-blob “yellow_tripdata_2022-01.parquet” --destination-container “source-data” --account-key [key] --account-name dridfdemosa --source-uri https://s3.amazonaws.com/nyc-tlc/trip data/yellow_tripdata_2022-01.parquetDann können Sie Ihre Azure Azure Data Factory anlegen:
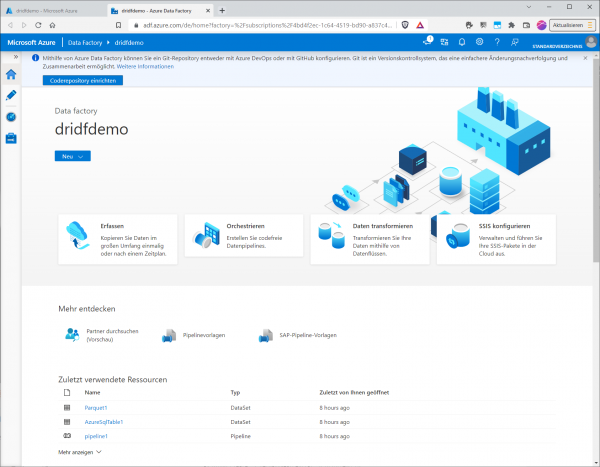
az datafactory create --factory-name dridfdemo --resource-group dridfdemo-rg –location germanywestcentralIst das erledigt, suchen Sie im Azure Portal nach Azure Data Factorys und klicken auf den Eintrag für die neu angelegte Datenfabrik.
:quality(80)/p7i.vogel.de/wcms/e9/90/e990f068cce6490e448c09d24e12dad0/0106195696.jpeg)
Die Übersichtsseite der Data Factory, hier klicken wir bei „Erste Schritte“ im Abschnitt „Azure Data Factory Studio öffnen“ auf „Öffnen“, um zum Azure Data Factory Studio zu gelangen.
:quality(80)/p7i.vogel.de/wcms/2d/c4/2dc44acb2a72a7ebe7e4d9477005c770/0106195701.jpeg)
Auf der Startseite des Data Factory Studios klicken wir dann links im Menü auf den Stift für „Autor“, um eine neue Pipeline anlegen zu können.
:quality(80)/p7i.vogel.de/wcms/6d/51/6d51f115ddaf8caf652221f174705105/0106195693.jpeg)
Nun besteht links unter „Factoryressourcen“ die Möglichkeit, jede beliebige Factory-Ressource zu erstellen. Die Reihenfolge spielt dabei keine Rolle, d. h. wenn Sie direkt mit einer Pipeline starten, können Sie Datasets und/oder Datenflüsse im Kontext der Pipeline erstellen. Klicken Sie nun einfach auf die drei Punkte neben „Pipelines“, um eine neue Pipeline erstellen zu können.
:quality(80)/p7i.vogel.de/wcms/54/70/5470f2670021e8325696ed237642e15f/0106195695.jpeg)
Nach dem Anlegen der Pipeline wählen Sie aus dem Menü bei „Aktivitäten“ einen „COPY DATA“-Task aus dem Abschnitt „Verschieben und Transformieren“, und ziehen ihn einfach per Drag-and-Drop in den Canvas-Bereich in der Mitte.
:quality(80)/p7i.vogel.de/wcms/42/76/427653b4edc4e33b6add9fda67848858/0106195694.jpeg)
Markieren Sie oben den Task, werden und die Registereiter „Allgemein“, „Quelle“, „Senke“, „Zuordnung“ und „Einstellungen“ sichtbar. An der kleinen „1“ bei Quelle und Senke erkennen Sie schnell, dass hier noch Konfigurationsschritte auf Sie warten. Beginnen Sie mit Quelle: Hier fügen Sie nun einen neues Dataset hinzu und wählen den Typ „Azure Blobspeicher“.
:quality(80)/p7i.vogel.de/wcms/23/4b/234be0e354cbc321c173caa32bdfc1ad/0106195755.jpeg)
Bei Format wählen Sie „Parquet“, denn das Dataset muss wissen, im welchen Format die die Quelldaten vorliegen.
:quality(80)/p7i.vogel.de/wcms/5a/61/5a61e149ba8e4bfd9dbd340328057c8c/0106195756.jpeg)
Nun müssen Sie einen „Verknüpften Dienst“ auswählen. Im Unterschied zum Dataset, das lediglich besagt, dass Quellendaten im Blob-Format vorliegen, geht es beim Linked Service konkret um die Konfiguration zur Anbindung Ihres speziellen Speicherkonto. Zur Authentifizierung und Autorisierung von Datenvorgängen stehen verschiedene Verfahren zur Verfügung. Wir verwenden hier SAS-URI, wozu Sie vorher für ihr Speicherkonto eine Konto-SAS (Shared Access Signature) erstellt haben müssten.
:quality(80)/p7i.vogel.de/wcms/c0/00/c000cc55ebfebea03b1c1261b02fa539/0106195754.jpeg)
Dann wählen Sie den Dateipfad, optional ein Verzeichnis und schließlich die hochgeladene Datei aus.
:quality(80)/p7i.vogel.de/wcms/67/79/6779aaf8b7bd390d730d4cb7b31ac199/0106195761.jpeg)
Sie können die Daten entweder manuell eintragen oder rechts auf den Dateiselektor klicken und die Datei mit der Maus auswählen.
:quality(80)/p7i.vogel.de/wcms/4c/75/4c7553a569877be768bc0bc58ab66889/0106195703.jpeg)
Im Ergebnis referenziert der verknüpfte Dienst nun die richtigen Quelldaten.
:quality(80)/p7i.vogel.de/wcms/b8/f4/b8f4b9fd95acec3ba03354765e732718/0106195765.jpeg)
Mit einem Klick auf „OK“ landen Sie wieder in Ihrer Pipeline. Die Quelle ist jetzt ausreichend konfiguriert, da sie keine „1“ mehr zeigt.
:quality(80)/p7i.vogel.de/wcms/d3/cf/d3cfa030937105cbe2e381a66b4f806f/0106195764.jpeg)
Nun müssen Sie die „Senke“ anschließen. Hier erstellen Sie wieder ein neues Dataset und wählen hier als Vorlage „Azure SQL Database“.
:quality(80)/p7i.vogel.de/wcms/30/5e/305e2bd04b3b9738bc61140d19cbabf1/0106195766.jpeg)
Bei „Verknüpfter Dienst“ konfigurieren Sie dann den Zugang zu Ihrer SQL-Datenbank. Zur Verbindungskonfiguration wählen Sie aus Ihren Azure-Abonnement Ihren SQL, Server, die SQL-Datenbank, wählen aus „Authentifizierungstyp“ die „SQL Authentifizierung“ aus und geben die Credentials an, die Sie beim Erstellen der Datenbank verwendet haben. Klicken Sie dann auf „Verbindung testen“ und dann auf „Erstellen“.
:quality(80)/p7i.vogel.de/wcms/19/e2/19e27d83be73209dc1c2f424107efdef/0106195763.jpeg)
Nun müssen Sie Ihrer Senke noch mitteilen, wie die Tabelle heißen soll, in der die Daten importiert werden.
:quality(80)/p7i.vogel.de/wcms/0b/66/0b6623b0dd2ad090a92e68b942c78536/0106195771.jpeg)
Da die Tabelle noch nicht existiert, können Sie sie auch nicht bei „Tabellenname“ auswählen. Daher klicken Sie unten auf den Link „Dieses Dataset öffnen“, setzen den Haken bei „Bearbeiten“ und geben einfach die gewünschten Tabellennamen an, z. B. „dbo“ und „taxidata“. Nun müssen wir aber noch dafür sorgen, dass die Tabelle automatisch angelegt wird.
:quality(80)/p7i.vogel.de/wcms/28/13/2813514ef0f02d0e985fe8e4eaacce1b/0106195776.jpeg)
Hierfür wechseln wir oben zum „Pipeline“-Reiter zurück und müssen im Reiter „Senke“ noch die Option „Tabelle automatisch erstellen“ setzen. Danach genügt ein Klick oben rechts auf „Debuggen“, um die Pipeline auszuführen.
:quality(80)/p7i.vogel.de/wcms/58/e0/58e0faffc616e917dc9fbb5d0a02f33b/0106195774.jpeg)
Nun sehen wir im Tab „Ausgabe“ erst einmal die ID der Pipelineausführung sowie Startzeit und Dauer. Der Typ ist „Daten kopieren“.
:quality(80)/p7i.vogel.de/wcms/19/d1/19d164dd6c17a29d9e2ef499490c1a77/0106195777.jpeg)
Nach ca. 20 Minuten sollte die Datei fertig kopiert sein und der Status auf grün wechseln.
:quality(80)/p7i.vogel.de/wcms/af/d9/afd9e16b5ca3f5423edd207c843d9940/0106195773.jpeg)
Nun bleibt nur zu prüfen, ob die Zieltabelle existiert.
:quality(80)/p7i.vogel.de/wcms/d8/42/d842f7412999c9d429c91c5ead577213/0106195781.jpeg)
Wenn Sie zufrieden sind, könnten Sie nun links oben im Tab „Alle veröffentlichen“ alle ihre letzten Änderungen final in der Live-Umgebung veröffentlichen.
Fazit
Der Microsoft SQL-Server besteht bekanntlich – sofern on-premises auf physischen oder virtuellen Servern betrieben – aus mehreren Bestandteilen; hierzu gehört auch die SQL Server Integration Services (SSIS), eine Plattform zum Erstellen von Datenintegrations- und Datentransformationslösungen auf Unternehmensebene.
Azure Data Factory können Sie sich als Cloud-Variante der SSIS vorstellen. Sie ist das Werkzeug in Azure zum Bewegen größerer Datenmengen oder um das Bewegen größerer Datenmengen zu koordinieren (Orchestrieren von Ladevorgängen), wobei die Begrifflichkeiten wie Pipelines, Datasets und Datenflüssen denen in SSIS ähneln. Wie einfach Data Factory einzusetzen ist, hat dieses Beispiel gezeigt.