
In nahezu allen Azure-Kursen wie z. B. im AZ 104 oder auch in meinem Kurs Azure Cloud Architect ist der Speicher-Dienst Azure-Storage thematisiert, da es sich hierbei um einen der wichtigsten Dienste in Azure handelt. Mit ihm können Sie Objektspeicher, Dateispeicher, Warteschlangen und Tabellenspeicher in Azure hosten. Ich stellte fest, dass es hier häufig Missverständnisse bzgl. der Access Tiers für Objekt- und Datei-Speicher gibt und dass es z. B. hinsichtlich Performance und Kosten lohnt, sich näher mit der Speicherarchitektur im Backend zu befassen.
Ich möchte das Thema Azure Storage jedoch nicht beim Urknall beginnen und auch nicht mit Adam und Eva, denn grundsätzlich sollte sich jeder Azure-Nutzer mit dem zentralen Speicherdienst der Microsoft-Cloud befasst haben. Beim Dienst Azure-Storage, bzw. der zugehörigen Azure-Entität „Storage Account“ handelt es sich um die zentrale Speichervirtualisierungslösung in Azure, die grundsätzliche die 4 oben genannten nativen softwaredefinierten Speicherdienste zur Verfügung stellt ergänzt um einige zusätzliche Funktionalitäten, die darauf aufbauen, wie z. B. Data Lake oder Static Website.
Ich konzentrieren mich hier auf beiden populärsten Dienste Objektspeicher (Blob) und Dateispeicher (File). Alle Dienste können über eine REST-API per HTTP ode Client-Bibliotheken (Azure Files versteht auch SMB) angesprochen und in eigene Anwendungen integriert werden, wobei das Autorisieren von Lese- und Schreibvorgängen je nach Dienst über Kontoschlüssel, Entra ID, signierte URLs oder ADDS (bei Azure Files) erfolgt. Lediglich Azure Files kennt zudem identitätsbasierte Authentifizierung und Autorisierung via Active Directory oder Entra ID Domain Services, was hier aber nicht thematisiert werden soll.
Storage Kosten
Ich möchte hier primär den Zusammenhang von Kosten und Performance darlegen. Die Kosten für Azure Storage setzen sich im Prinzip stets aus verbrauchter Speicherkapazität, Transaktionen und ausgehender Datenübertragung zu anderen Azure-Regionen sowie zum Internet zusammen; im Detail differiert die Kostenstruktur jedoch abhängig vom jeweiligen Dienst (Blob, Files, usw.). Interessierte können den Zusammenhang auch ohne Azure-Konto gut im Azure Preisrechner nachvollziehen.
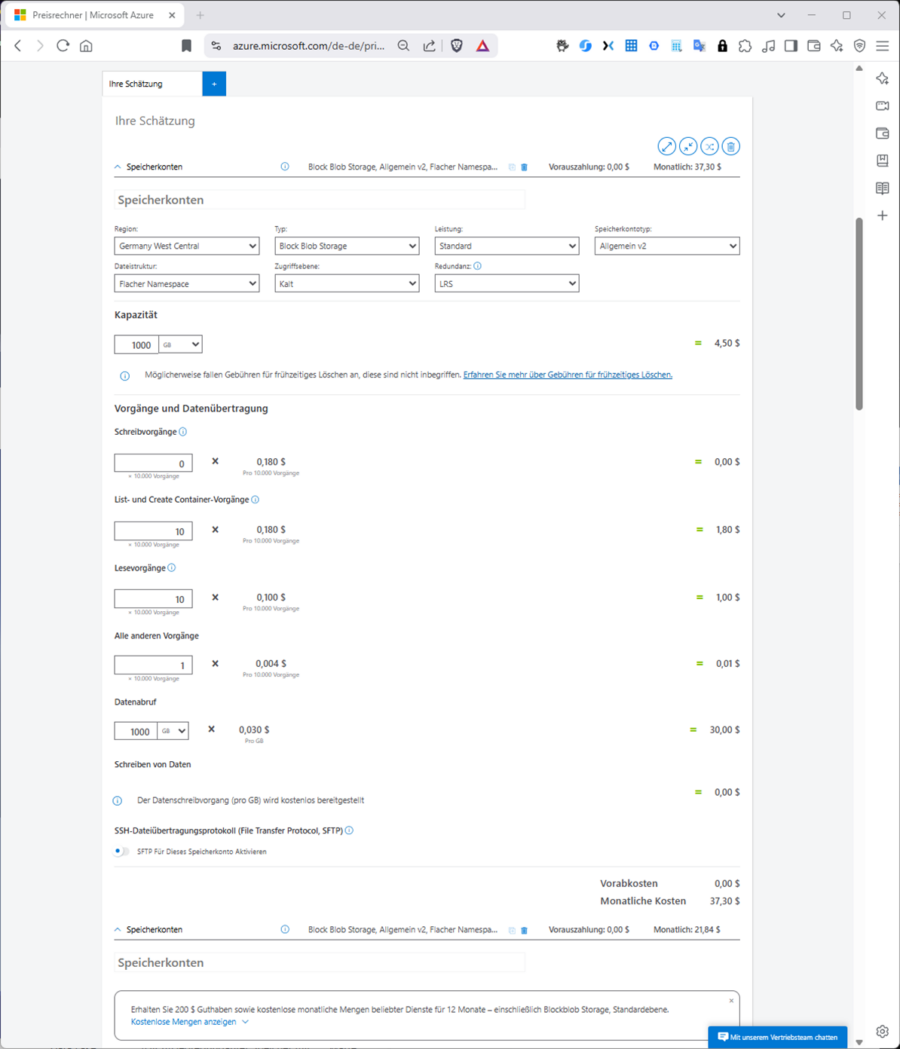
So kostet beispielsweise 1 TB Objektspeicher (Type: Block Blob Storage, Dateistruktur: Flacher Namespace) in der kalten Zugriffsebene mit lokaler Redundanz in Deutschland in der Aufbewahrung derzeit 4,50 USD. Transaktionen (Vorgänge) werden in Päckchen von je 10000 Vorgängen berechnet, wobei Schreibvorgänge mit 0,18 USD pro 10000 Vorgänge ganz grob das Doppelte kosten wie Lesevorgänge (0,1 USD pro 10000).
Die ausgehende Datenübertragung (Datenabruf) wird pro GB und Monat berechnet. Sie können testweise annehmen, dass Sie das gesamte Terrabyte gespeicherter Daten auch abrufen. Bei den Transaktionen müssen Sie schätzen; ich bin in der Abbildung exemplarisch von 100000 Schreib- und Lesevorgängen ausgegangen. Eine „0“ mehr oder weniger macht den Kohl aber nicht fett, d. h. Sie sind bei Objektspeicher (Blob) in Summe mit 37,30 USD im Monat dabei für ein ganzes Terrabyte Cloud-Speicher, wobei die Datenübertragung den weitaus größten Anteil ausmacht.
Außerdem variieren Kosten in Abhängigkeit davon, ob der Speicherdienst im Backend SSD- oder HDD-Seicher nutzt. Dies hängt bekanntlich vom Kontotyp (Standard, Premium Block Block, Premium Page Blobs oder Premium Files) ab. Alle Premium-Speichertypen speichern auf SSDs, dafür unterstützt nur der Standard-Typ alle 4 genannten Speicherdienste. Auf den Unterschied von Block-, Page- und Append-Blobs bin ich hier eingegangen.
Ebenfalls die Kosten beeinflusst das gewählte Redundanzmodell (LRS, ZRS, GRS, GZRS). Bei GRS belegen Sie faktisch die doppelte Speicherkapazität wegen der Replikation in die Koppel-Region. Das Replikationsmodell legen Sie auf Konto-Ebene fest. Es lässt sich aber, genauso wie der Kontotyp (Letzterer mit Einschränkungen) auch im Nachgang ändern. Da es sich bei Azure-Storage (unabhängig vom gewählten Speicherdienst) um einen verteilten Datenspeicher handelt, kommt dem physischen sowie dem logischen Speichermodell in mehrfacher Hinsicht eine große Bedeutung zu. In Bezug auf die (Lese)Konsistenz (nachdem Daten geschrieben wurden) ist zu erwähnen, dass Azure-Storage im Rahmen des gewählten Redundanz-Modells in der primären Region (LRS, ZRS, GRS Primärseite) stets mit einer vollständig synchronen Replikation arbeitet. Lediglich die GRS innewohnende zusätzliche Replikation in der Koppel-Region erfolgt asynchron. Die Durability ist so oder so beachtlich.
- LRS mit 3 synchronen Replikaten auf 3 Servern in einem Rechenzentrum (was vor Rack-, Server- und Plattenausfällen schützt) beträgt sie 99,999999999 %
- ZRS mit 3 synchronen Replikaten drei Verfügbarkeitszonen (was vor Rechenzentrum-, Rack-, Server- und Plattenausfällen schützt) beträgt sie 99,9999999999 %
- GRS mit 3 synchronen Replikaten auf 3 Servern in einem Rechenzentrum + anschließender asynchroner Replik in die Koppel-Region (was vor Regions, Rack-, Server- und Plattenausfällen schützt) beträgt sie 99,99999999999999 %)
- GZRS kombiniert ZRS mit GRS, verteilt also die 3 synchronen primären Kopien auf 3 Verfügbarkeitszonen.
Soweit zum physischen Speichermodell auf Konto-Ebene, zu dem sich Microsoft aber im Detail nicht weiter einlässt. Die weiteren Betrachtungen im Zusammenhang von Kosten und Performance beziehen sich auf das logische Speichermodell des jeweiligen Dienstes.
Zugriffs-Ebenen
Werfen wir zunächst einen Bick auf die Zugriffsebenen für Objekt- und Dateispeicher. Sowohl bei Azure-Blob, als auch bei Files gibt es „Heiß“ (HOT), und „Kühl“ (COOL). Bei Blob hingegen gibt es zusätzlich „Kalt“ (COLD) und „Archiv“ …
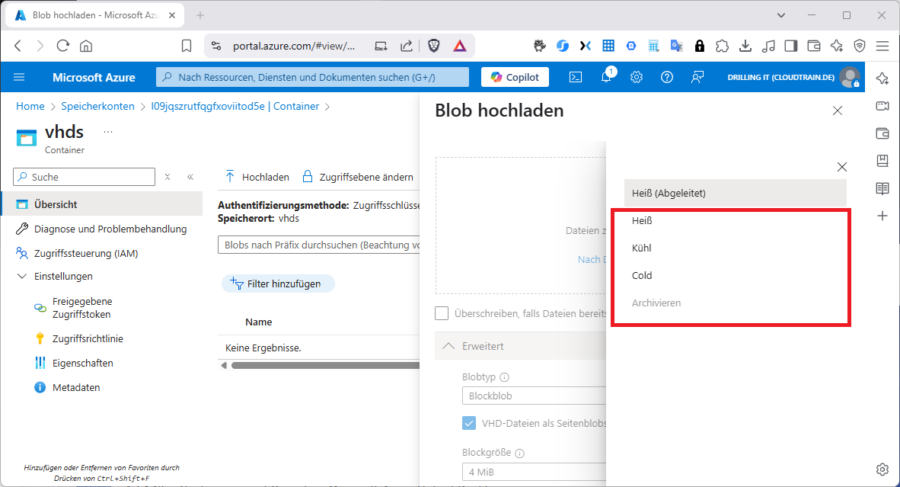
… während es bei Datei-Speicher zusätzlich „Transaktion optimiert“ und „Premium“ gibt.
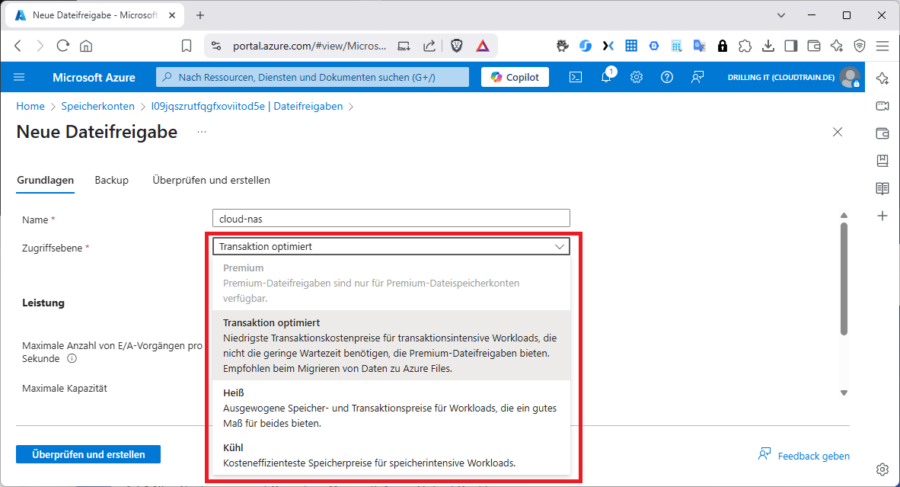
Hier ist es wichtig zu verstehen, dass die beiden Arten von Zugriffsebene von Blob und Files nichts miteinander zu tun haben; auch nicht „Heiß“ und „Kühl“, die es ja in beiden Modellen gibt. Gemeinsam haben Sie aber alle, dass Sie Preis und Performance beeinflussen.
Performance und Zugriffsebenen in Azure Blob Storage
Zunächst ein paar allgemeine Überlegungen zur Blob-Performance: Azure Storage hat Skalierbarkeits- und Leistungsziele für die Kapazität, Transaktionsrate und Bandbreite (Durchsatz). Beginnen wir mit den Transaktionen: Einzelne Blobs erlauben bis zu 5000 Transaktionen pro Sekunde; das gesamte Speicherkonto unterstützt in den meisten Regionen 20000 Transaktionen pro Sekunde. Schauen wir auf die Bandbreite: Einzelne Blobs erlauben in den meisten Regionen einen Durchsatz von 60 MB/s; das gesamte Speicherkonto unterstützt einen Durchsatz von bis zu 60 Gbps. Im Detail wird hierbei noch zwischen ein- und ausgehenden Daten unterschieden.
Die Latenz hingegen ist die Wartezeit oder Antwortzeit, die eine Anwendung auf den Abschluss einer Anforderung warten muss. Die Wartezeit kann sich direkt auf die Leistung einer Anwendung auswirken. Wie oben schon erwähnt, wird die Latenz im Wesentlichen durch den Kontotyp (Standard: HDD, Premium: SSD) bestimmt. Die Azure Storage-Latenz bezieht sich auf Anforderungsraten für Azure Storage-Vorgänge (Transaktionen). Anforderungsraten werden meist in Form von IOPS (Input/Output operations per second) angegeben. Die Azure Storage-Bandbreite hingegen (Durchsatz) bezieht sich auf die Anforderungsrate und lässt sich durch Multiplikation von Anforderungsrate (IOPS) und Anforderungsgröße errechnen.
Bedenken Sie aber auch: Die Verarbeitung von Azure Storage Anforderungen beansprucht natürlich CPU- und Arbeitsspeicherressourcen des Clients. Kommt es am Client zu einem Engpass, z. B. wegen Überlastung, stehen weniger Ressourcen für die Verarbeitung von Azure Storage Anforderungen zur Verfügung. Jede Art von Konflikt oder Mangel an Client-Ressourcen erhöht quasi die Ende-zu-Ende-Latenz. Die Server-Latenz hingegen bleibt in diesem Fall unverändert.
Ebenfalls Auswirkungen haben die Netzwerkschnittstelle und die Netzwerk-Pipeline zwischen dem Client und dem Dienst Azure Storage. Allein schon die physische Entfernung kann erhebliche Auswirkungen haben, wenn sich z. B. die Client-VM in einer anderen Azure-Region oder gar in Ihrer lokalen Umgebung befindet. Ein VPN ist in letzterem Fall nicht erforderlich, da Blob-Storage per REST-API über einen öffentlichen Endpunkt angefragt wird. Ein leistungsstarker IPSEC-Tunnel und ein privater Endpunkt oder Express Route Public Peering können aber durchaus Verbesserungen bewirken.
Blob Storage Partitionierung
Da es sich bei Blob-Speicher um ein verteiltes Speichermodell handelt, in dem Sie große Binärobjekte speichern können, spielt nicht nur das gewählte Access-Tier eine große Rolle, sondern auch der Blob-Typ. der wiederum vom Konto-Typ abhängt. In einem Szenario, in dem Sie sehr große Datenmengen schnell hochladen oder herunterladen müssen, sollten Sie Block-Blobs verwenden. Hier haben Sie die Wahl zwischen Standard- und Premium-Speicherkonten. Page-Blobs hingegen sind nützlich für Anwendungen, die „zufälligen“ Zugriff auf Teile der Daten erfordern wie z. B. virtuelle Festplatten von VMs (VHDs). In diesem Fall brauchen Sie zwingend ein Premium-Speicher-Konto.
Da jedes Block- oder Page-Blob in einem „Container“ in einem Azure-Speicherkonto gespeichert ist, richtet sich die Nutzungsphilosophie nach dem Use Case, d. h. Sie gruppieren „verwandte“ Blobs, welche z. B. die gleichen Lebenszyklus-, Sicherheits- oder Leistungsanforderungen haben, im selben Container.
Die Gruppierung ist nicht physischer, sondern logischer Art, weil ja ohnehin jedes Blob einen eindeutigen Namen (Objektschlüssel) hat. Dieser beeinflusst nämlich die Partitionierung und wird daher auch Partitionsschlüssel genannt. Für jedes Blob setzt er sich aus Konto-Name, Container-Name und Blob-Name zusammen.
Letztendlich partitioniert der gewählte Partitionsschlüssel die Daten in „Bereiche“, welche sich möglichst gleichmäßig über die gesamte verteilte Speicherschicht ausbreiten, d. h. Blobs können über viele Server verteilt sein, um den Zugriff darauf zu skalieren. Jedes Blob kann aber immer auch von nur einem einzelnen Server bereitgestellt werden. Daher spielt Ihr „Benennungsschema“, also der Objektschlüssel eine entscheidende Rolle, damit es z. B. nicht zu übermäßigem Datenverkehr zu nur einer Partition kommt (Hot-Table-Problem). Man kann es auch so ausdrücken: Organisieren Sie Ihre Daten mit Hilfe von Zeitstempeln oder numerischen Bezeichnern, sollten Sie sicherstellen, dass Sie keine Datenverkehrsmuster verwenden, bei denen Daten nur angefügt (oder vorangestellt) werden, weil sich derartige Muster nicht für ein bereichsbasiertes Partitionierungssystem eignen.
Im Folgenden habe ich einige Beispiele für gute und schlechte Partitionsschlüssel aufgeführt.
Beispiele für „gute“ Partitionsschlüssel (Objektbenennungsschema) wären … Beispiele für „wenige gute“ Partitionsschlüssel (Objektbenennungsschema) wären …
Damit also nicht der gesamte Datenverkehr für einen Vorgang von einem einzelnen Partitionsserver übertragen werden muss, ist es häufig nützlich, dem jeweiligen Namen einen mehrstelligen Hash voranzustellen. Übrigens erfolgen die Aktionen zum Schreiben eines einzelnen Blocks oder einer einzelnen Seite stets atomisch. Sie können übrigens beim Upload eines Blobs, auch die Block-Größe beeinflussen. So empfiehlt es sich, bei Standard- und Premium-Speicherkonten Blob- oder Blockgrößen von mehr als 256 KiB zu wählen. Durch höhere Blob- oder Blockgrößen werden automatisch Block-Blobs mit hohem Durchsatz aktiviert.
Access Tiers
Kommen wir nun zu den Zugriffsebenen: Die Access Tiers beeinflussen sowohl die Kosten als auch die Performance. Microsoft klassifiziert das so:
- HOT-Tier (Heiß): Optimiert für niedrige Latenz und häufigen Zugriff, typischerweise im Bereich von Millisekunden
- COOL-Tier (Kühl): Etwas höhere Latenz als HOT-Tier, aber immer noch im Bereich von Millisekunden.
- ARCHIVE-Tier (Archiv): Höhere Latenz, da die Daten erst rehydriert werden müssen, was mehrere Stunden dauern kann. Die beiden erstgenannten Zugriffsebenen werden daher auch als „Online“-Ebenen bezeichnet.
Diese Werte können je nach Netzwerkbedingungen, Größe der Blobs und anderen Faktoren variieren. Es ist wichtig, dass Sie die spezifischen Anforderungen Ihrer Anwendung berücksichtigen und gegebenenfalls Tests einplanen, welche möglichst die optimale Konfiguration finden.
Das HOT-Tier ist also für häufigen Zugriff optimiert. Dies bedeutet, dass die Daten schnell und effizient abgerufen werden können, was zu niedrigen Latenzzeiten führt. Die Zugriffsebenen beeinflussen aber nicht nur die Art- und Weise, wie die Daten abgelegt werden und im geringen Umfang, die Latenzen (sowie anderen Faktoren, die die Performance beeinflussen können, wie z. B. „Caching“), sondern vor allem auch den Preis.
Rufen Sie sich die oben skizzierten Kosten-Optionen in Erinnerung, besteht der kostenmäßige Unterschied zwischen HOT- und COOL vorrangig im unterschlichen „Verhältnis“ der Abruf- zu den Aufbewahrungs-Kosten (Kapazität). Bei HOT sind Abrufe (im Verhältnis gesehen) günstiger, bei COOL die Kapazität, Abrufe aber selbstverständlich trotzdem möglich. HOT ist daher ideal für Daten, die regelmäßig gelesen und geschrieben werden. In Grunde bieten zwar Beide Ebenen weitgehend „ähnliche“ Latenzzeiten für den Datenzugriff, das HOT-Tier ist aber teurer in Bezug auf Speicher (günstiger bei häufigem Zugriff), das COOL-Tier ist kostengünstiger für die Speicherung, aber teurer bei Zugriffen.
Wie Sie der Abbildung oben entnehmen können, gibt es heuer sogar 4 verschiedene Zugriffs-Ebenen (HOT, COOL, COLD und Archive), bzw. „Heiß“, „Kühl“, „Kalt und „Archiv“ für Blob-Storage. Microsoft hat die dritte Online-Ebene (COLD) am 10.08.2023 eingeführt. Die Speicherkosten sind hier noch etwas günstiger als bei COOL, die Abrufe etwas teuer als bei COOL. Damit eignet sich COLD für Daten, die sehr selten abgerufen werden, aber dennoch sofort verfügbar sein müssen, wie z.B. Archivdaten, die gelegentlich doch benötigt werden. Außerdem gibt es hier eine Mindesthaltezeit von 90 Tagen (gegenüber 30 Tagen bei COOL).
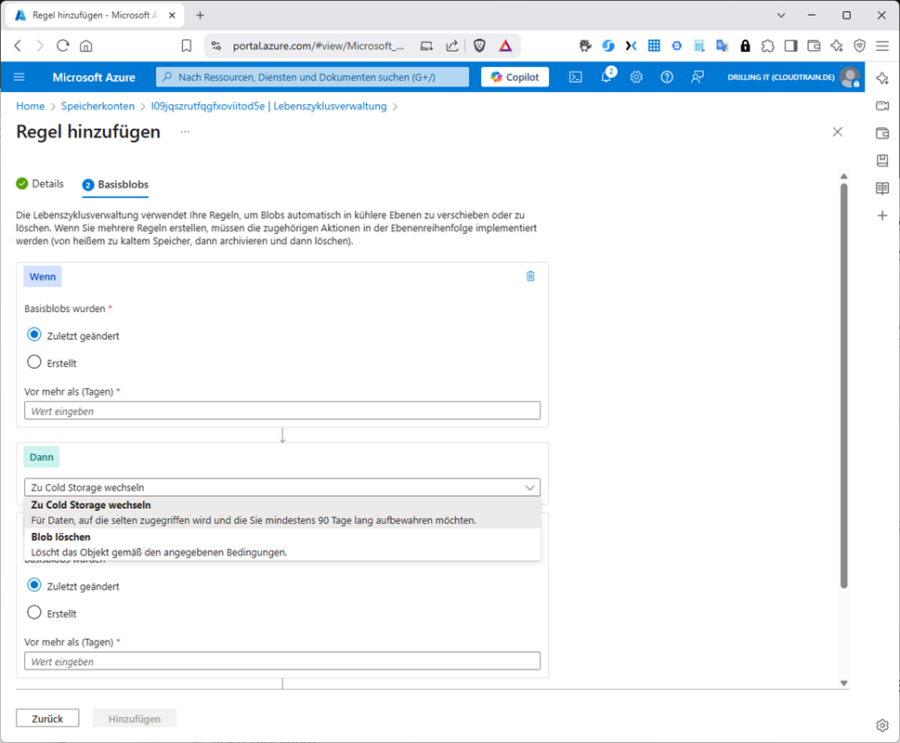
Da Daten eine ihnen innewohnende Natur der Ausalterung haben, können Sie den Übergang zwischen den einzelnen Blob-Access-Tiers mit Hilfe von Lifecyle-Policies automatisieren, d. h. Sie definieren hier „Wenn-Dann“-Regeln, die sich wahlweise auf den Zeitpunkt der letzten Änderungen oder der Erstellung des Basis-Blobs beziehen für die einzelnen Übergangsarten „Zu Cold Storage wechseln“ oder „Blob löschen“.
Im zweiten Teil dieses Beitrages betrachten wir Performance-Aspekte von Datei-Speicher in Azure Storage (Azure Files) und sehen uns an, dass die formal ähnlichen Access-Tiers bei Azure Files eine ganz andere Bedeutung haben.